
1.命名空间
C++引入命名空间(namespace)机制的主要目的是解决命名冲突问题,并提高代码的组织性和可维护性。以下是具体原因和背景:
避免命名冲突:
在大型项目或使用多个第三方库时,不同的库或模块可能定义了同名的函数、类或变量。例如,两个库都可能定义一个名为print的函数。如果没有命名空间,这些同名标识符会冲突,导致编译错误或意外行为。
命名空间通过将标识符限制在特定的作用域内(如std::cout或mylib::print),有效隔离不同模块的命名,防止冲突。
提高代码组织性:
命名空间允许开发者将相关功能分组,逻辑上组织代码。例如,C++标准库使用std命名空间来包含所有标准库功能(如std::vector、std::string),使代码结构更清晰。
开发者可以根据模块、功能或项目需求自定义命名空间(如company::module::function),便于管理和阅读。
支持大规模开发:
在团队协作或大型项目中,不同开发者可能无意中定义同名标识符。命名空间提供了一种机制,确保各部分代码可以独立开发而不会相互干扰。
它还支持嵌套命名空间,进一步细化代码组织,例如namespace outer::inner。
向后兼容和扩展性:
命名空间机制在C++98中引入,旨在改进C语言的全局命名问题,同时保持与C的兼容性。全局作用域仍然存在,但开发者可以选择使用命名空间来更好地管理代码。
它也为标准库的扩展提供了空间,新的功能可以添加到std或其他命名空间中,而不会破坏现有代码。
简化代码重用:
命名空间使得代码可以在不同项目或上下文中重用,而无需担心名称冲突。例如,一个库的开发者可以将所有功能放入专属命名空间,方便用户在不同项目中引入。
我们可以定义自己的命名空间,相当于给定一个库,通过命名空间指定这个库内的函数及相关内容,可以有效的避免因同名函数带来的困扰。
#include <iostream>
// 定义一个命名空间
namespace MyNamespace {
// 命名空间内的变量,具有命名空间作用域
int namespaceVar = 20;
void printVar() {
std::cout << "Inside MyNamespace: namespaceVar = " << namespaceVar << std::endl;
}
int globalVar = 0;
}
namespace MyNamespace2 {
int globalVar = 0;
}
int main() {
// 使用命名空间前缀访问变量
std::cout << "Outside MyNamespace: namespaceVar = " << MyNamespace::namespaceVar << std::endl;
MyNamespace::printVar(); // 访问命名空间内的函数
return 0;
}
2.软件的存储区域
在C++中,内存存储通常可以大致分为几个区域,这些区域根据存储的数据类型、生命周期和作用域来划分。这些区域主要包括:
代码区(Code Segment/Text Segment):
存储程序执行代码(即机器指令)的内存区域。这部分内存是共享的,只读的,且在程序执行期间不会改变。
举例说明:当你编译一个C++程序时,所有的函数定义、控制结构等都会被转换成机器指令,并存储在代码区。
全局/静态存储区(Global/Static Storage Area):
存储全局变量和静态变量的内存区域。这些变量在程序的整个运行期间都存在,但它们的可见性和生命周期取决于声明它们的作用域。
举例说明:全局变量(在函数外部声明的变量)和静态变量(使用
static关键字声明的变量,无论是在函数内部还是外部)都会存储在这个区域。
栈区(Stack Segment):
存储局部变量、函数参数、返回地址等的内存区域。栈是一种后进先出(LIFO)的数据结构,用于存储函数调用和自动变量。
举例说明:在函数内部声明的变量(不包括静态变量)通常存储在栈上。当函数被调用时,其参数和局部变量会被推入栈中;当函数返回时,这些变量会从栈中弹出,其占用的内存也随之释放。
堆区(Heap Segment):
由程序员通过动态内存分配函数(如
new和malloc)分配的内存区域。堆区的内存分配和释放是手动的,因此程序员需要负责管理内存,以避免内存泄漏或野指针等问题。举例说明:当你使用
new操作符在C++中动态分配一个对象或数组时,分配的内存就来自堆区。同样,使用delete操作符可以释放堆区中的内存。
常量区(Constant Area):
存储常量(如字符串常量、const修饰的全局变量等)的内存区域。这部分内存也是只读的,且通常在程序执行期间不会改变。
举例说明:在C++中,使用双引号括起来的字符串字面量通常存储在常量区。此外,使用
const关键字声明的全局变量,如果其值在编译时就已确定,也可能存储在常量区。
#include <iostream>
#include <cstring> // 用于strlen
// 全局变量,存储在全局/静态存储区
int globalVar = 10;
// 静态变量,也存储在全局/静态存储区,但仅在其声明的文件或函数内部可见
static int staticVar = 20;
void func() {
// 局部变量,存储在栈区
int localVar = 30;
// 静态局部变量,虽然声明在函数内部,但存储在全局/静态存储区,且只在第一次调用时初始化
static int staticLocalVar = 40;
std::cout << "Inside func:" << std::endl;
std::cout << "localVar = " << localVar << std::endl;
std::cout << "staticLocalVar = " << staticLocalVar << std::endl;
// 尝试通过动态内存分配在堆区分配内存
int* heapVar = new int(50);
std::cout << "heapVar = " << *heapVar << std::endl;
// 释放堆区内存(重要:实际使用中不要忘记释放不再使用的堆内存)
delete heapVar;
}
int main() {
// 访问全局变量
std::cout << "Inside main:" << std::endl;
std::cout << "globalVar = " << globalVar << std::endl;
std::cout << "staticVar = " << staticVar << std::endl; // 注意:staticVar在外部不可见(除非在同一个文件中或通过特殊方式)
// 调用函数,展示栈区和堆区的使用
func();
// 字符串常量通常存储在常量区,但直接访问其内存地址并不是标准C++的做法
// 这里我们仅通过指针来展示其存在
const char* strConst = "Hello, World!";
// 注意:不要尝试修改strConst指向的内容,因为它是只读的
std::cout << "strConst = " << strConst << std::endl;
// 尝试获取字符串常量的长度(这不会修改常量区的内容)
std::cout << "Length of strConst = " << strlen(strConst) << std::endl;
return 0;
}
3. 程序的编译过程
C++程序的编译过程是一个相对复杂但有序的过程,它涉及将高级语言(C++)代码转换为机器可以执行的低级指令。在这个过程中,通常会生成几个中间文件,包括.i(预处理文件)、.s(汇编文件)和.o(目标文件或对象文件)。下面是这个过程的详细解释:
1. 预处理(Preprocessing)
输入:C++源代码文件(通常以
.cpp或.cxx为后缀)。处理:预处理器(通常是
cpp)读取源代码文件,并对其进行宏展开、条件编译、文件包含(#include)等处理。输出:生成预处理后的文件,通常具有
.i后缀(尽管这个步骤可能不是所有编译器都会自动生成.i文件,或者可能需要特定的编译器选项来生成)。
2. 编译(Compilation)
输入:预处理后的文件(如果有的话,否则直接是源代码文件)。
处理:编译器(如
g++、clang++等)将预处理后的文件或源代码文件转换为汇编语言代码。这个步骤是编译过程的核心,它执行词法分析、语法分析、语义分析、中间代码生成、代码优化等任务。输出:生成汇编文件,通常具有
.s或.asm后缀。
3. 汇编(Assembly)
输入:汇编文件。
处理:汇编器(如
as、gas等)将汇编语言代码转换为机器语言指令(即目标代码),但这些指令仍然是针对特定架构的,并且尚未被链接成可执行文件。输出:生成目标文件(或对象文件),通常具有
.o、.obj或.out后缀。
4. 链接(Linking)
输入:一个或多个目标文件,以及可能需要的库文件(如C++标准库)。
处理:链接器(如
ld、lld等)将目标文件和库文件合并成一个可执行文件或库文件。在这个过程中,链接器会解决外部符号引用(即函数和变量的调用),并将它们链接到正确的地址。输出:生成可执行文件(在Unix-like系统中通常是
.out、.exe或没有特定后缀,在Windows系统中是.exe)。
我们在cmakelist中直接去修改以下,就可以将程序的中间文件输出出来
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -save-temps=obj")
set(CMAKE_C_FLAGS "${CMAKE_CXX_FLAGS} -save-temps=obj")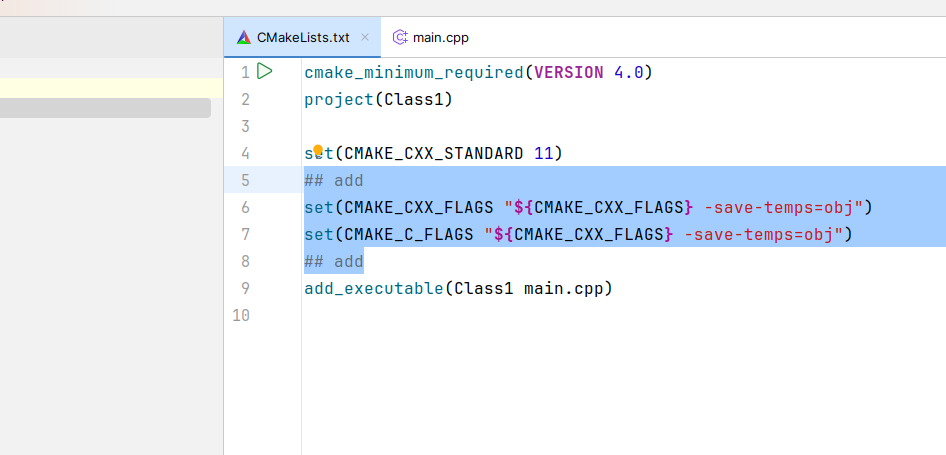
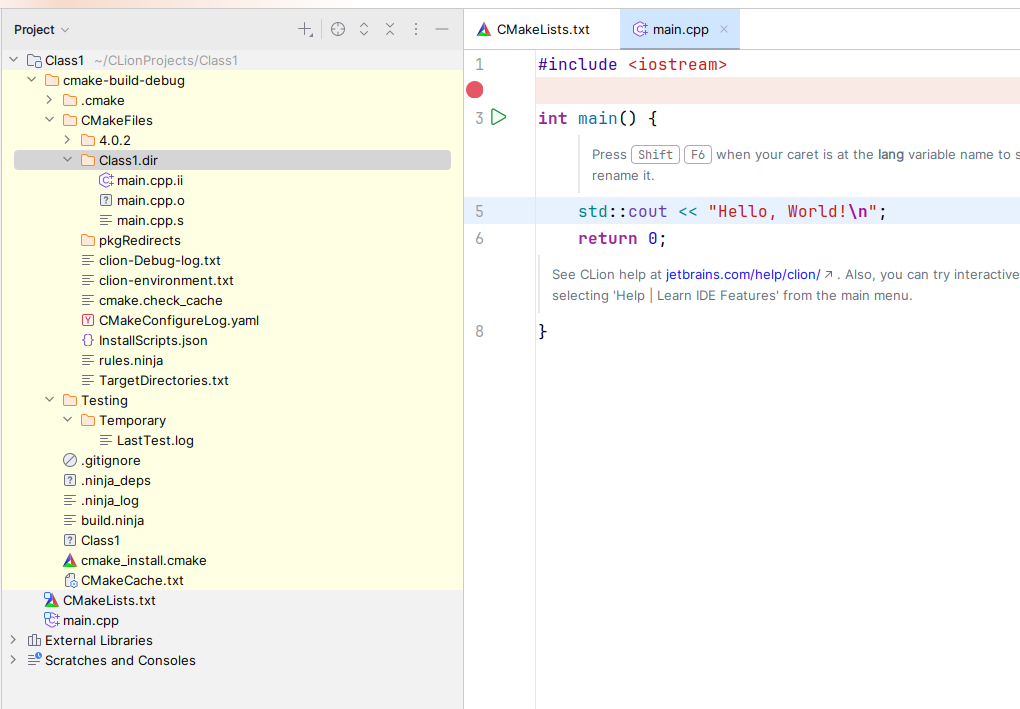
.i文件是预处理后的文件,包含了所有宏展开、条件编译和文件包含的结果。.s文件是汇编文件,包含了将C++代码转换为汇编语言后的结果。.o文件是目标文件或对象文件,包含了汇编器生成的机器语言指令,但尚未被链接成可执行文件。
这些文件在编译过程中扮演了重要的角色,帮助开发者理解和调试代码,同时也是编译链中不可或缺的一部分。不过,值得注意的是,并非所有编译器都会默认生成.i和.s文件,这可能需要特定的编译器选项来启用。
4.防卫式声明
pragma once作用
工作方式:
#pragma once是一个非标准的但广泛支持的预处理指令,它告诉编译器该头文件在单个编译过程中只应被包含一次。编译器在第一次遇到#pragma once时会记住该文件名,并在后续的包含操作中忽略它。优点:简单、直观、易于使用。不需要生成唯一的宏名,减少了出错的可能性。
缺点:不是 C++ 标准的一部分,尽管大多数现代编译器都支持它,但在某些旧的或特定的编译器中可能不受支持。
使用场景:在支持
#pragma once的编译器中,推荐使用它作为防止头文件重复包含的首选方法。
宏定义(#ifndef, #define, #endif)
工作方式:通过宏定义(通常称为“包含卫士”或“头文件保护”)来防止头文件被重复包含。首先检查一个特定的宏是否已定义,如果没有定义,则定义它并包含头文件的其余部分。如果宏已经定义,则跳过头文件的其余部分。
优点:是 C++ 标准的一部分,因此在所有 C++ 编译器中都是可用的。
缺点:需要为每个头文件生成一个唯一的宏名,这可能会增加出错的机会(例如,如果两个头文件不小心使用了相同的宏名)。
使用场景:在需要确保代码与所有 C++ 编译器兼容时,或者在不支持
#pragma once的编译器中,使用宏定义来防止头文件重复包含。
总结
尽管 #pragma once 和 宏定义在功能上相似,但它们在实现方式和使用场景上有所不同。在大多数现代 C++ 项目中,推荐使用 #pragma once,因为它更简单、更直观,并且大多数现代编译器都支持它。然而,在需要确保与所有 C++ 编译器兼容的情况下,或者在不支持 #pragma once 的环境中,仍然需要使用宏定义来防止头文件被重复包含。

评论区